【玩转 GPU】本地部署大模型--ChatGLM(尝鲜篇)
本文主要介绍ChatGLM-6B 的本地部署,提供更保姆级别的教程,让完全不懂技术的同学,也能在本地部署大模型~
在19年曾经尝试过使用GPT2进行代码补全,当时就被大模型效果惊艳到啊,只是没想到短短3年多,大模型效果提升这么快。学不完,根本学不完....
大模型实在太火了,终于还是忍不住对它下手。今天介绍如何在本地部署大模型尝鲜,后面有时间会持续出大模型技术原理篇。
1 大语言模型LLM
大语言模型(Large Language Model),是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。LLM的特点是规模庞大,包含数十亿的参数,帮助它们学习语言数据中的复杂模式。这些模型通常基于深度学习架构,如转化器,这有助于它们在各种NLP任务上取得令人印象深刻的表现。
语言模型的发展
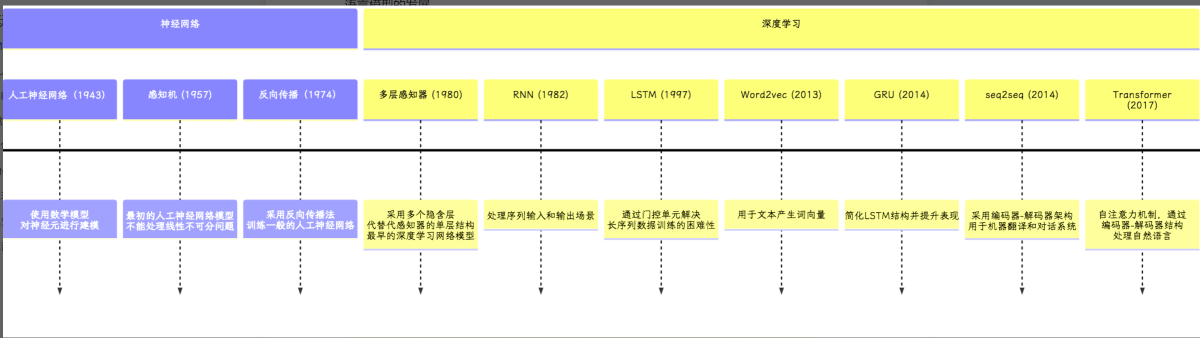
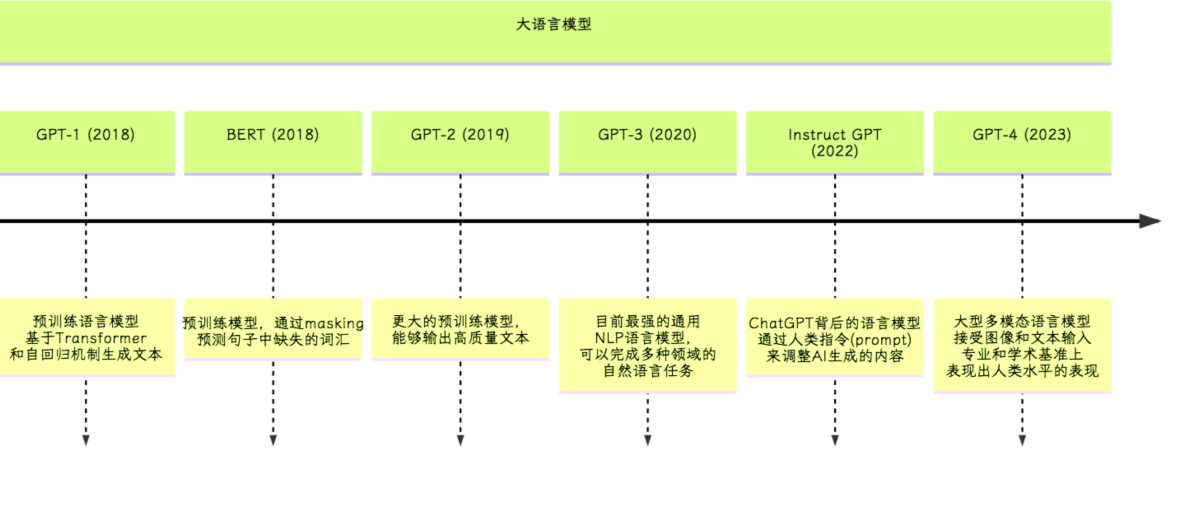
从2017年google提出Transformer后,各种基于transformer的变形结构被提出和使用。主要分类两类,一种是基于encoder,最具代表的BERT模型;一种是基于decoder,最具代表的openAI提出的GPT系列。现在明显GPT在LLM领域处于领先地位了,特别ChatGPT的问世。
2 GPU相关知识
以下回答均来自ChatGPT
2.1 GPU和CPU有什么区别
GPU和CPU是两种不同的计算机处理器,它们在设计和功能上有很大的区别。
CPU(中央处理器)是计算机的主要处理器,它负责执行计算机的指令和控制计算机的操作。CPU通常有几个核心,每个核心可以处理一个线程。CPU的设计目的是为了处理通用计算任务,例如操作系统、应用程序和游戏等。
GPU(图形处理器)是专门设计用于处理图形和图像的处理器。GPU通常有数百个甚至数千个小型处理单元,这些处理单元可以同时处理多个任务。GPU的设计目的是为了加速图形和图像处理任务,例如游戏、视频编辑和机器学习等。
因此,GPU和CPU在设计和功能上有很大的区别。GPU比CPU更适合处理大规模的并行计算任务,例如机器学习和深度学习等。而CPU则更适合处理通用计算任务,例如操作系统和应用程序等。
GPU可以对AI深度学习模型加速的原因有以下几点:
并行计算能力:GPU拥有大量的小型处理单元,这些处理单元可以同时处理多个任务,因此GPU比CPU更适合处理大规模的并行计算任务。在深度学习中,许多计算任务可以被分解为大量的小型计算任务,这些计算任务可以被并行处理,因此GPU可以大大加速深度学习模型的训练和推理。
浮点运算能力:深度学习模型中的计算任务通常涉及大量的浮点运算,例如矩阵乘法和卷积等。GPU拥有专门的浮点运算单元,可以高效地执行这些计算任务,因此GPU比CPU更适合处理深度学习模型中的计算任务。
内存带宽:深度学习模型通常需要大量的数据进行训练和推理,因此内存带宽对于深度学习模型的性能至关重要。GPU拥有高速的内存带宽,可以高效地读取和写入大量的数据,因此GPU可以大大加速深度学习模型的训练和推理。
综上所述,GPU可以对AI深度学习模型加速的原因是它具有强大的并行计算能力、高效的浮点运算能力和高速的内存带宽,这些特性使得GPU比CPU更适合处理深度学习模型中的计算任务。
2.2 常见GPU芯片
几种常用的GPU芯片及其优缺点对比:
1. NVIDIA GeForce系列
优点:NVIDIA GeForce系列是目前市场上最流行的GPU芯片之一,具有强大的计算能力和广泛的应用支持。NVIDIA GeForce系列的GPU芯片适用于游戏、图形处理、机器学习和深度学习等领域。
缺点:NVIDIA GeForce系列的GPU芯片相对较贵,而且功耗较高,需要较大的散热器和电源支持。
2. AMD Radeon系列
优点:AMD Radeon系列是另一种流行的GPU芯片,具有较高的性价比和广泛的应用支持。AMD Radeon系列的GPU芯片适用于游戏、图形处理和机器学习等领域。
缺点:AMD Radeon系列的GPU芯片相对于NVIDIA GeForce系列的GPU芯片来说,计算能力稍弱,而且在一些应用程序中的性能表现不如NVIDIA GeForce系列的GPU芯片。
3. Intel Xe系列
优点:Intel Xe系列是英特尔公司推出的新一代GPU芯片,具有强大的计算能力和广泛的应用支持。Intel Xe系列的GPU芯片适用于游戏、图形处理、机器学习和深度学习等领域。
缺点:Intel Xe系列的GPU芯片相对于NVIDIA GeForce系列和AMD Radeon系列的GPU芯片来说,计算能力稍弱,而且目前市场上的产品较少,应用支持相对较少。
4. Apple M系列
优点:Apple M系列是苹果公司推出的新一代GPU芯片,具有强大的计算能力和低功耗特性。Apple M系列的GPU芯片适用于苹果电脑和移动设备等领域。
缺点:Apple M系列的GPU芯片目前只适用于苹果设备,应用支持相对较少,而且相对于其他GPU芯片来说,计算能力稍弱。
综上所述,不同的GPU芯片具有不同的优缺点,选择适合自己需求的GPU芯片需要综合考虑计算能力、应用支持、价格和功耗等因素
2.3 A100芯片特点
NVIDIA A100是NVIDIA公司推出的一款新一代GPU芯片,以下是它的优缺点和价格:
优点:
1. 强大的计算能力:NVIDIA A100采用了新一代的Ampere架构,具有强大的计算能力和高效的能源利用率。它可以在深度学习、机器学习和科学计算等领域中提供卓越的性能。
2. 高速的内存带宽:NVIDIA A100采用了HBM2内存,具有高速的内存带宽和低延迟,可以高效地处理大规模的数据集。
3. 支持多任务并行处理:NVIDIA A100具有多个Tensor Core处理单元,可以同时处理多个任务,提高了计算效率。
缺点:
1. 高昂的价格:NVIDIA A100的价格相对较高,不适合所有用户。
2. 需要高端的硬件支持:NVIDIA A100需要高端的散热器和电源支持,以确保稳定的性能和长期的使用寿命。
价格:
NVIDIA A100的价格因型号和配置而异,一般来说,单个A100 GPU的价格在5000美元到10000美元之间。此外,NVIDIA还提供了一些基于A100芯片的服务器和超级计算机解决方案,价格更高。
总的来说,NVIDIA A100是一款强大的GPU芯片,具有高效的计算能力和内存带宽,适用于深度学习、机器学习和科学计算等领域。但是,它的价格相对较高,需要高端的硬件支持,不适合所有用户。
显存(Graphics Memory)是指GPU(图形处理器)中的内存,用于存储图形和图像数据。显存是GPU中的一种高速缓存,可以快速读取和写入图形和图像数据,以提高图形和图像处理的效率。
A100的显存容量有多种配置可供选择,最大可达到40GB。以下是NVIDIA A100显存容量的几种配置:
40GB HBM2显存:这是NVIDIA A100的最大显存配置,可以提供最高的性能和内存带宽,适用于大规模的深度学习和机器学习任务。
20GB HBM2显存:这是NVIDIA A100的中等显存配置,可以提供较高的性能和内存带宽,适用于中等规模的深度学习和机器学习任务。
10GB HBM2显存:这是NVIDIA A100的最小显存配置,可以提供较低的性能和内存带宽,适用于小规模的深度学习和机器学习任务。
需要注意的是,NVIDIA A100的显存容量不仅影响GPU的性能,还会影响GPU的价格。显存容量越大,GPU的价格也越高。因此,在选择NVIDIA A100时,需要根据具体的应用场景和预算选择适合的显存配置。
3 chatGLM-6B本地部署
上文说过大模型的一个特点就是大规模参数,需要高规模大显存配置,而显存是需要资金的。调用chatGPT不仅需要资金还需要一些其他门槛。
但是现在有很多开发者,对自研的大模型进行开源,更好支持中文,更友好的部署环境。比如ChatGLM-6B。
git:https://github.com/THUDM/ChatGLM-6B
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
本文就主要介绍ChatGLM-6B 的本地部署,虽然readme已经介绍很详细,本文会提供更保姆级别的教程,可以让完全不懂技术的同学,也能在本地部署大模型~
3.1 环境确认
首先我们要确认自己的机器环境是否能支持chatGLM能在本地跑起来,不然白安装环境。
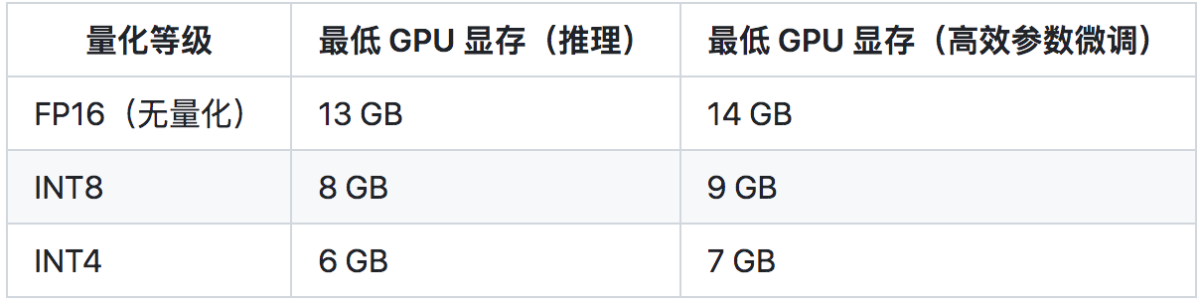
如果没有 GPU 硬件的话,也可以在 CPU 上进行推理,但是推理速度会更慢。使用方法如下(需要大概 32GB 内存),本文就不介绍CPU部署了~尝试过,很慢。。
如何确认自己PC是否支持GPU呢?
计算机右击–>管理–>设备管理器–>显示适配器

不是所有显卡都能使用CUDA编程。CUDA是NVIDIA公司开发的一种并行计算平台和编程模型,它可以利用GPU的并行计算能力加速计算密集型任务。CUDA编程需要使用NVIDIA的GPU,因此只有搭载NVIDIA GPU的计算机才能使用CUDA编程。
此外,不是所有的NVIDIA GPU都支持CUDA编程。CUDA编程需要使用支持CUDA的NVIDIA GPU,例如GeForce、Quadro、Tesla等系列的GPU。不同的GPU系列和型号支持的CUDA版本和功能也有所不同,需要根据具体的GPU型号和CUDA版本进行选择。
3.2 安裝Cuda和cudnn
cuda和cudnn的安裝很多教程,就不进行详细的介绍,主要就是要注意版本。
安装cuda
https://zhuanlan.zhihu.com/p/99880204
安装cudnn
https://developer.nvidia.com/rdp/cudnn-archive
nvidia-smi查看下cuda的版本
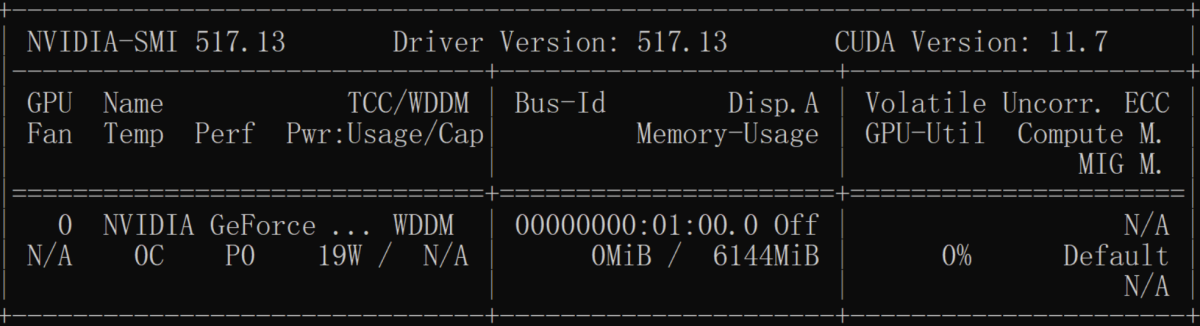
如果nvcc和nvidia-smi显示的版本不一致,可以参考
https://www.jianshu.com/p/eb5335708f2a
3.3 部署模型
3.3.1 clone源码
GitHub:https://github.com/THUDM/ChatGLM-6B
3.3.2 安装包
建议先建立一个conda环境
conda create -n cahtglmb
根据自己机器的配置选择和显卡对应的torch版本
https://pytorch.org/get-started/previous-versions/
安装torch
conda install pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.7 -c pytorch -c nvidia
验证cuda和torch是否可用
import torchprint(torch.__version__)print(torch.cuda.is_available())
安装其他包,源码中的requments.txt
pip install -r requirements.txt
3.3.3 本地运行
环境配置好后,我们就可以在本地运行chatGLM了,运行以下代码:
# -*- coding: utf-8 -*-"""-------------------------------------------------
Description: 本地调用chatGLM,支持命令行交互
Author: zoey
Date: 2023/6/3 12:05-------------------------------------------------"""import fire
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)# 使用CPU跑模型
# model = AutoModel.from_pretrained("THUDM/chatglm-6b-int4", trust_remote_code=True).float()# 使用GPU跑4位量化模型
model = AutoModel.from_pretrained("THUDM/chatglm-6b-int4", trust_remote_code=True).half().cuda()model = model.eval()def infer():
while True:
request = input("你好,我是chatglm-6b >>> ")
history = []
while not request:
print('Prompt should not be empty!')
request = input("Model prompt >>> ")
response, _history = model.chat(tokenizer, request, history=history)
history = _history print('\033[1;31m{}\033[0m'.format(request) + '\033[1;33m{}\033[0m'.format(response))
if __name__ == '__main__':
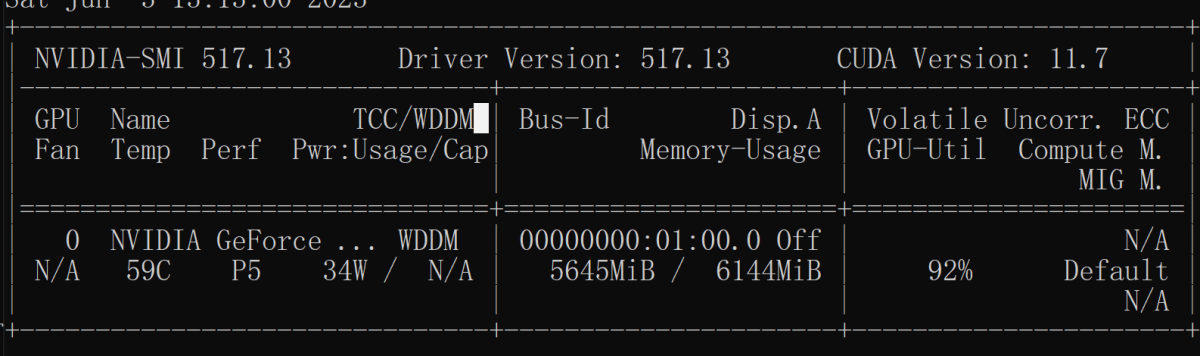
fire.Fire(infer)我们可以和ChatGLM对话:

运行起来,风扇呼呼的~
闪电发卡ChatGPT产品推荐:
ChatGPT独享账号:https://www.chatgptzh.com/post/86.html
ChatGPT Plus共享账号:https://www.chatgptzh.com/post/319.html
ChatGPT Plus独享账号(购买充值代充订阅):https://www.chatgptzh.com/post/306.html
ChatGPT APIKey购买充值(直连+转发):https://www.chatgptzh.com/post/305.html
ChatGPT Plus国内镜像逆向版:https://www.chatgptzh.com/post/312.html
ChatGPT国内版(AIChat):https://www.chatgptzh.com/post/318.html